

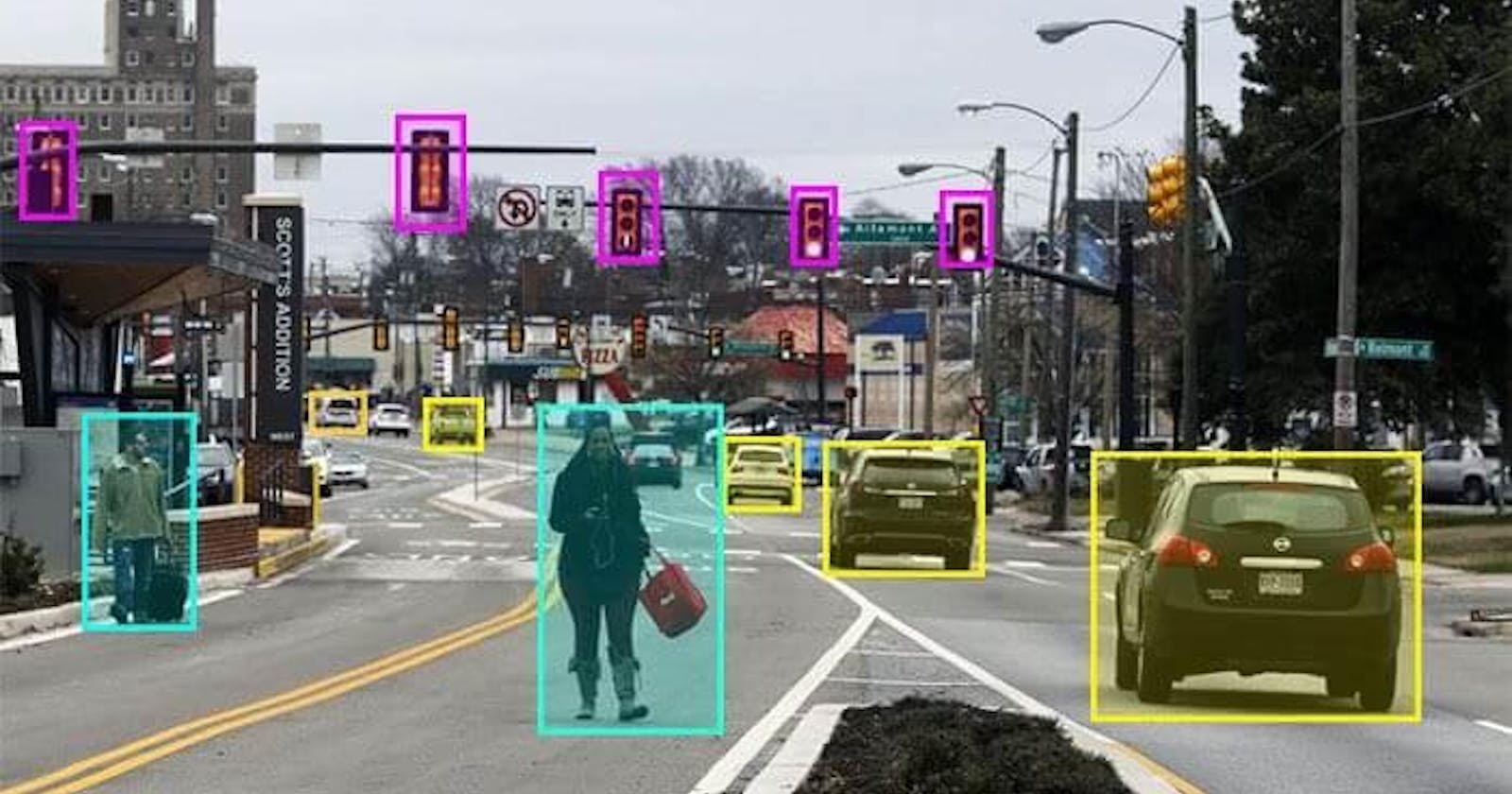
A bounding box is a type of annotation used in computer vision that refers to a box drawn around an object in an image or video. The coordinates of the bounding box can be used to represent the object's location, size, and orientation.
There are various ways to compute bounding boxes, but the most common approach is to use a sliding window, where a grid is overlaid on the image, and each grid cell is classified as containing an object or not. If the classifier predicts that a thing is present in a given cell, the box is drawn around that cell.
Bounding boxes are often used in object detection algorithms, where the goal is to identify all objects in an image and draw a box around each one. They can also be used for tracking objects over time in video data.
How Does Bounding Box Deep Learning Work?
To understand how bounding box deep learning works, it's first essential to understand the basics of deep learning. Deep learning is a type of machine learning that uses artificial neural networks to learn from data.
Neural networks are similar to the brain in that they are composed of a series of layers, each containing a set of nodes (or neurons). The nodes in the first layer of the network receive input from the data, and the nodes in subsequent layers receive information from the nodes in the previous layer. The output of the final layer is used to make predictions about the data.
In order to train a deep learning model, we need to specify the structure of the network (i.e., the number of layers and the number of nodes in each layer) and then train the model on a dataset. The training process adjusts the weights of the connections between nodes so that the output of the final layer is as close as possible to the actual labels for the data.
Once a deep learning model has been trained, it can be used to make predictions about new data. To do this, we pass the new data through the network and use the output of the final layer to make our predictions.
Now that we understand how deep learning works let's look at how it can be used for bounding box detection.
Bounding box deep learning models are typically composed of an object detector and a regressor. The object detector is responsible for identifying which pixels in an image belong to an object, and the regressor is responsible for predicting the coordinates of the bounding box around that object.
The most common approach for training these models is to pre-train the object detector on a large dataset of images containing many different objects. This can be done using a deep learning model such as a convolutional neural network (CNN). Once the object detector has been trained, it can be used to identify objects in new images.
The output of the object detector will typically be a set of bounding boxes around the detected objects, along with a confidence score for each bounding box.
The regressor is then trained on these bounding boxes to learn how to predict the coordinates of the tightest possible bounding box around an object. After both the object detector and regressor have been trained, they can be combined into a single model that can be used to detect and localize objects in new images.
So far, we have seen how bounding box deep learning models can be used to detect objects in an image. However, these models can also detect objects in video sequences. In this case, the model will be trained to predict the coordinates of the bounding box for each frame in the video sequence.
As you can see, bounding box deep learning is a powerful tool for detecting and localizing objects in images and video. However, like any other type of deep learning, it is not without its limitations. For example, these models are often limited by the available training data, and it can take a long time to train them on large datasets.
In addition, they can only be used on images or videos containing previously labeled objects. This means that if you want to use these models to detect objects in an image, you will first need to label all of the objects in that image.
The Benefits of Bounding Box Deep Learning
Real-time object detection: One of the significant benefits of bounding box deep learning is that it can be used to detect objects in real time. This is because the object detector can be implemented as a CNN, which can be run on a GPU for efficient inference. But, this inference process is not enough to achieve real-time object detection.
Improved accuracy: bounding box deep learning models can achieve better accuracy than traditional object detection methods. This is because the regressor can learn from many bounding boxes and produce more accurate predictions.
Faster training: bounding box deep learning models can be trained faster than traditional object detection models. This is because CNN can be trained on many images in parallel, which speeds up the training process. This can be done with much less computational power than traditional object detection models.
Less data: bounding box deep learning models require less training data than traditional object detection models. This is because CNN can learn from many images, reducing the amount of data needed to train the model.
The Drawbacks of Bounding Box Deep Learning
Requires labeled data: One of the significant drawbacks of bounding box deep learning is that it requires a large amount of labeled data to train the model. This can be expensive and time-consuming to obtain, especially if the goal is to identify objects in the real world with various shapes, sizes, and colors.
Limited to rectangular shapes: another drawback of bounding box deep learning is limited to rectangular shapes. This means that it may not accurately detect objects that are not rectangular.
May miss small objects: another potential drawback of bounding box deep learning is that it may miss small objects. This is because the model is trained on images with a fixed size and aspect ratio, so it may not be able to accurately detect smaller objects that are closer to the camera or outside of the frame.
May have difficulty with occlusion: bounding box deep learning may also have trouble with occlusion or objects that are partially hidden by other objects. This is because the model is trained on images where all objects are visible and unoccluded, so it may not be able to accurately detect objects covered by other items in the frame of view.
Conclusion
Is Bounding Box Deep Learning the Future of Video Annotation?
Bounding box deep learning has several benefits that make it well-suited for video annotation. In particular, its ability to detect objects in real-time and improve accuracy with fewer data make it an attractive option for many video annotation tasks.
However, some drawbacks should be considered before using this approach.